Abstract
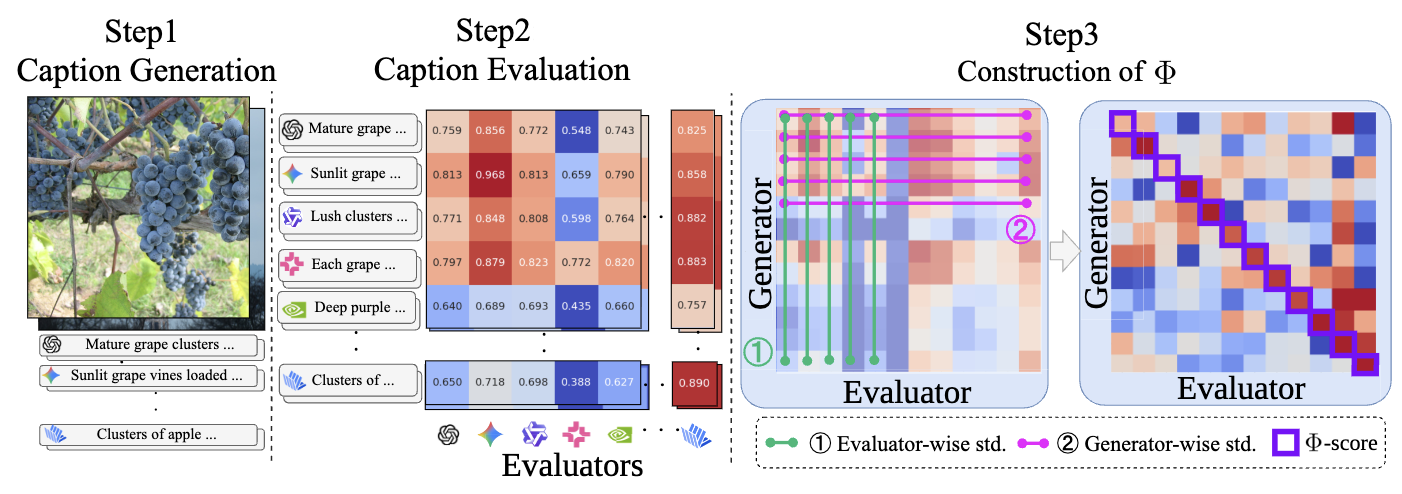
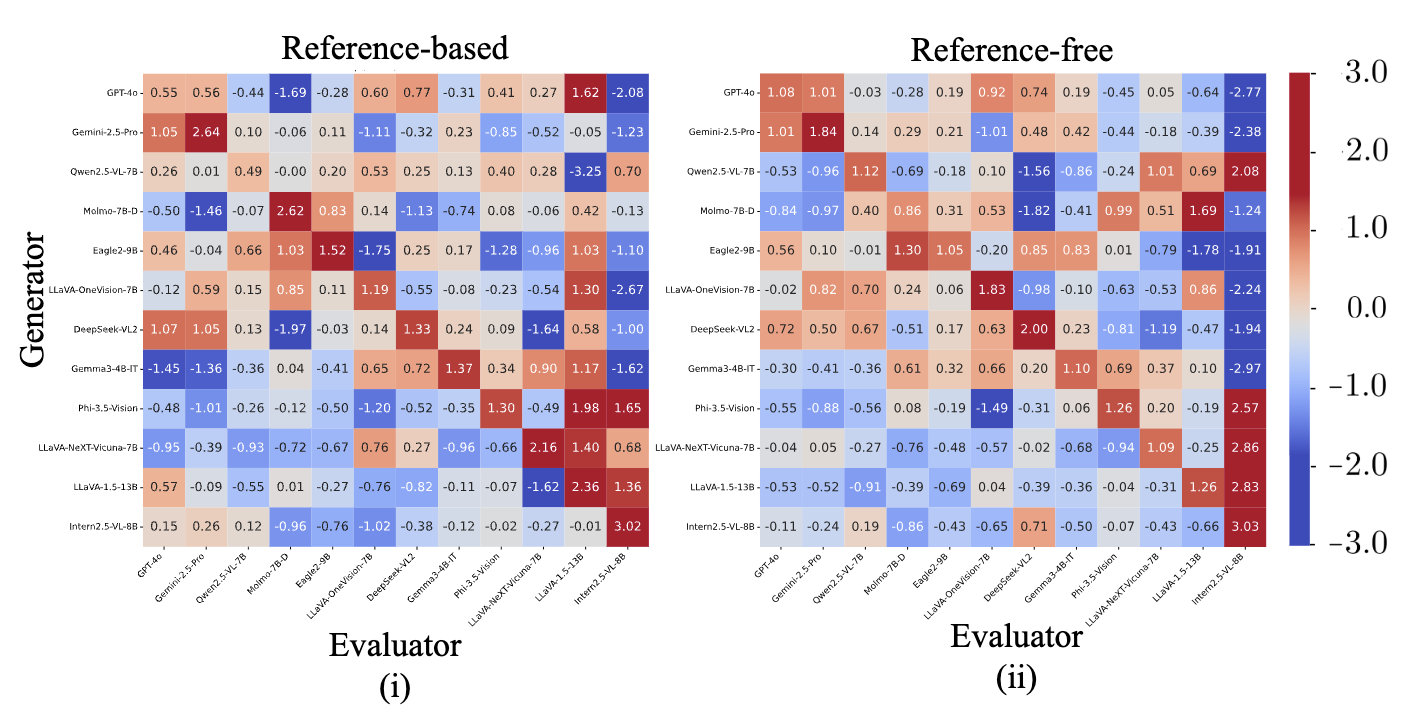
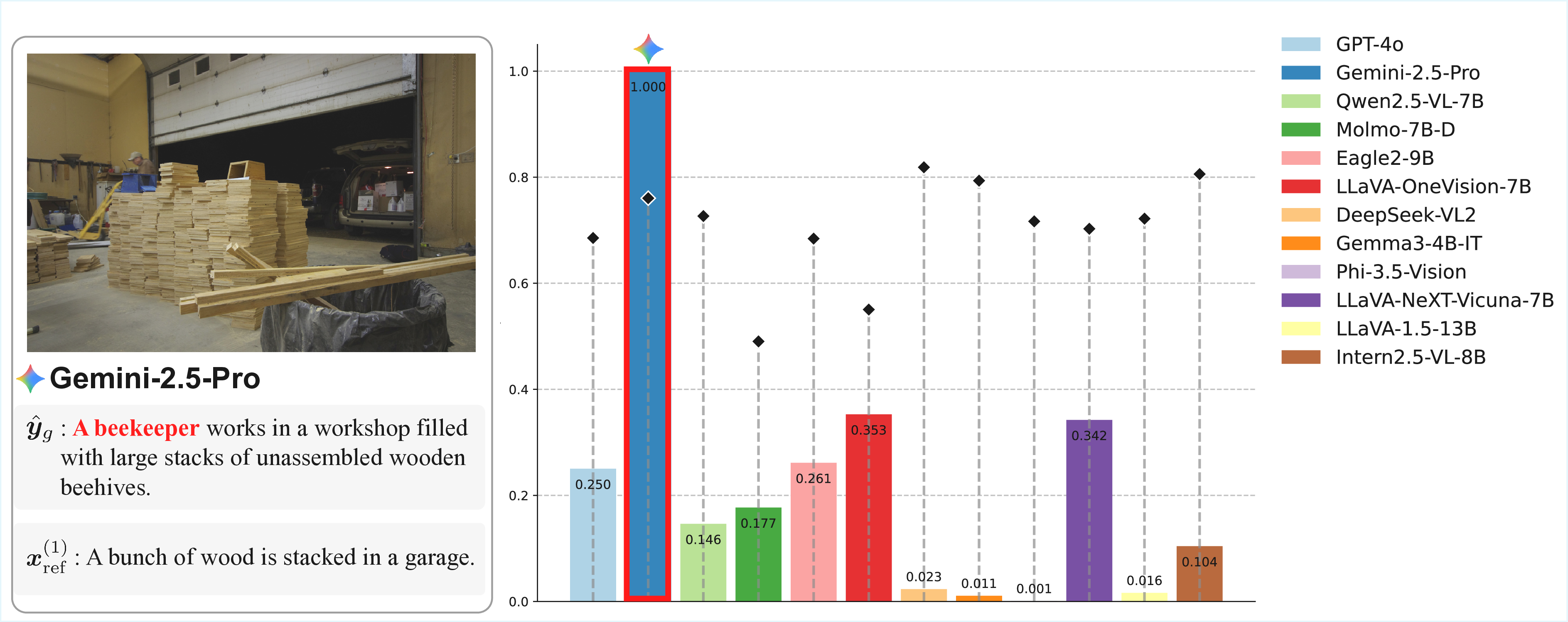
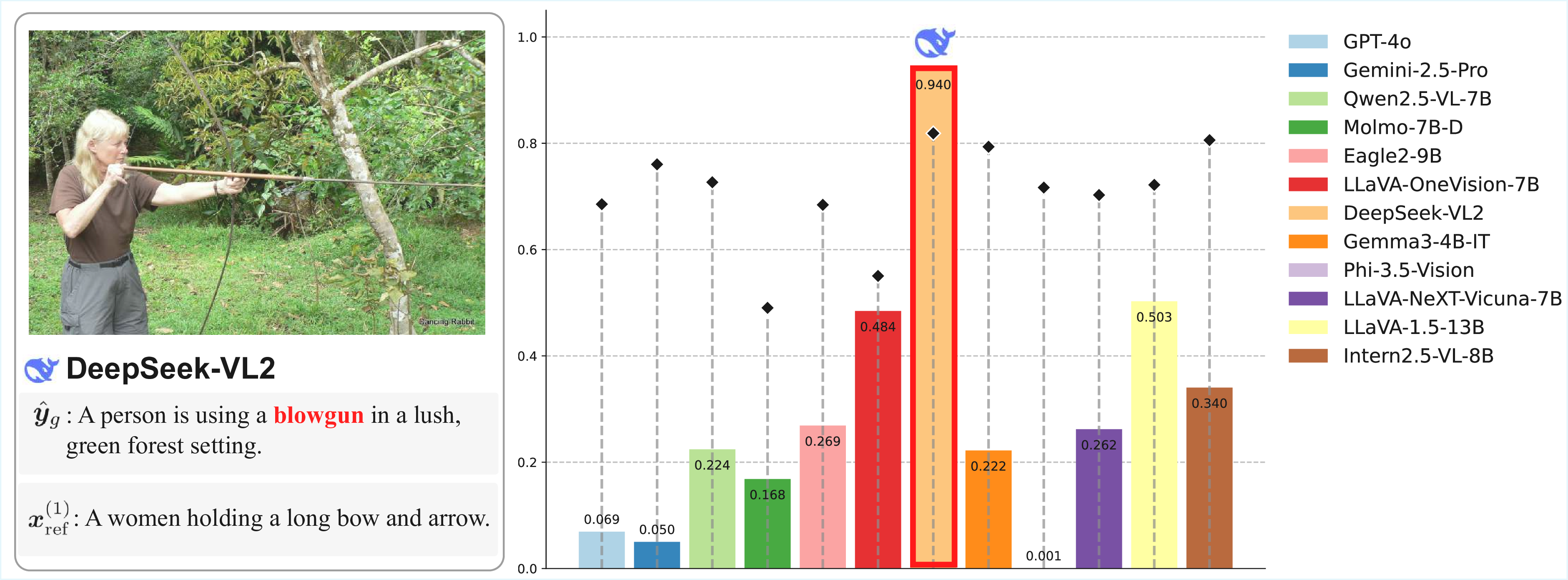
Automatic evaluation using multimodal large language models (MLLMs), commonly referred to as MLLM-as-a-Judge, has been widely used to measure model performance. If such MLLM-as-a-Judge methods were biased, they could distort model comparisons and benchmark-driven scientific progress. However, it remains unclear to what extent MLLM-as-a-Judge methods favor or disfavor text generated by specific MLLMs. In this study, we propose Philautia-Eval to investigate such model-specific preference bias. Philautia-Eval quantifies the degree of the bias by disentangling preference tendencies from differences in generation quality. Using 1.29M caption-score pairs collected from 12 MLLMs, we found that representative MLLMs tend to exhibit self-preference bias. Moreover, experimental results indicate mutual preference bias within particular model families, which is potentially driven by reused connectors and overlapping instruction-tuning resources. Finally, we introduce a simple ensemble of MLLMs, Pomms. Our results demonstrated that Pomms effectively mitigated the model-specific preference bias while maintaining performance. Our project page and code are provided in the supplementary materials.
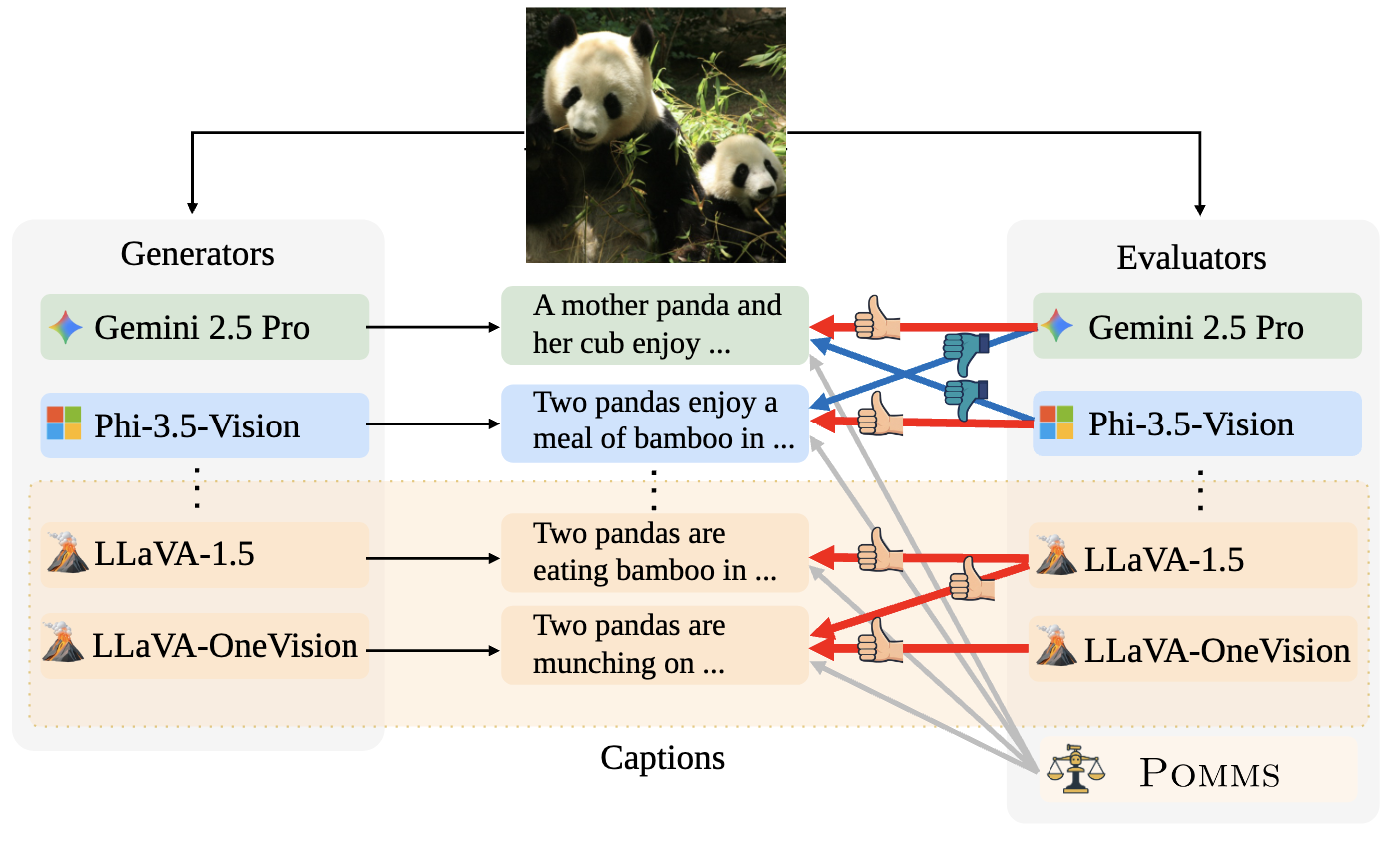
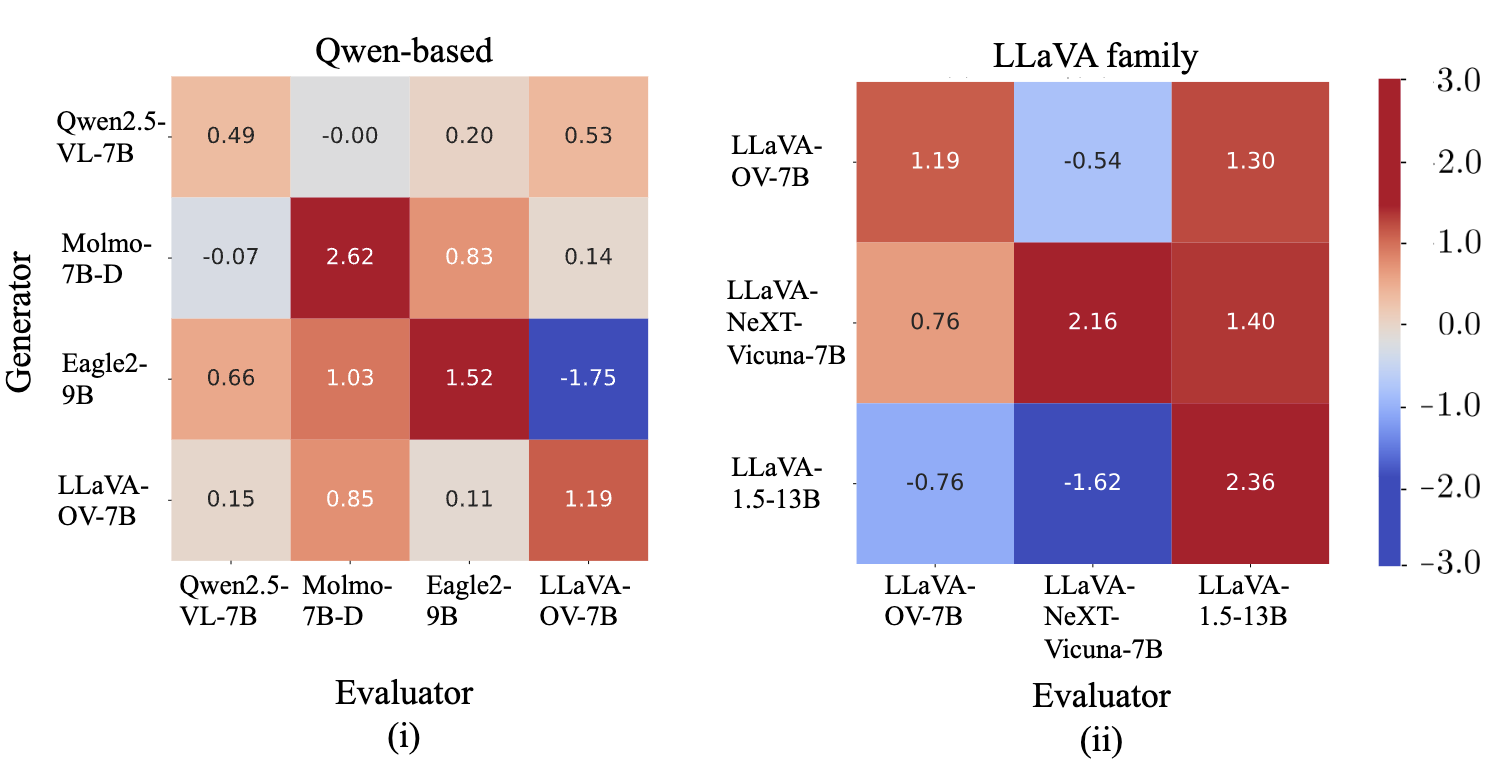
Schematic of our approach for investigating model-specific preference bias in MLLM-as-a-Judge. Each MLLM typically favors its own generations (self-preference bias), whereas LLaVA-1.5 favors text generated by other models within the LLaVA family (cross-model preference bias). Our Panel of MLLM Evaluators (Pomms) exhibits less model-specific preference bias.